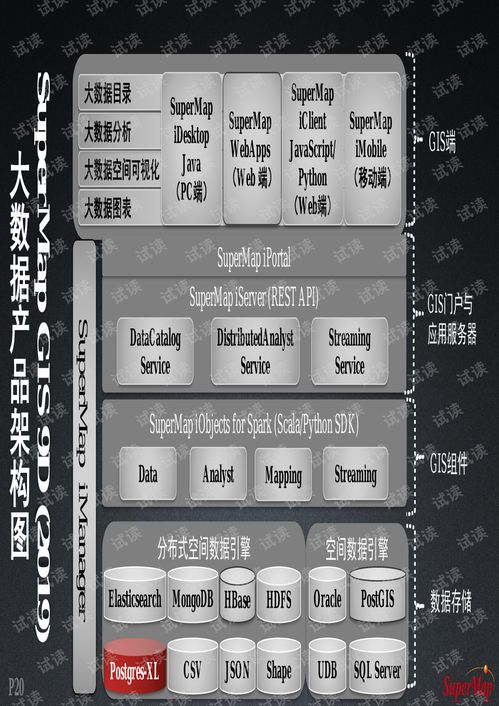
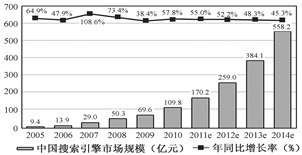
构筑智能未来 人工智能最佳利用的数据基础设施与基础软件开发策略

随着人工智能技术的飞速发展,如何高效、可靠地利用数据并开发强大的基础软件,已成为推动AI应用落地的关键。人工智能的最佳利用不仅依赖于先进的算法模型,更离不开坚实的数据基础设施和灵活高效的基础软件开发。本文将探讨这两大核心要素的需求与建设路径。
一、数据基础设施:AI的“燃料库”与“高速公路”
数据是人工智能的“燃料”,而数据基础设施则是存储、管理和输送这些燃料的“高速公路”与“仓库”。一个优秀的数据基础设施应满足以下需求:
- 高可扩展性与弹性存储:AI应用常需处理海量数据,基础设施需支持横向扩展,能够灵活应对数据量的爆发式增长。云原生存储、分布式文件系统(如HDFS)和对象存储(如Amazon S3)成为主流选择。
- 高质量数据管理与治理:数据质量直接影响AI模型效果。需建立完善的数据治理框架,包括数据清洗、标注、版本控制和元数据管理。数据湖(Data Lake)与数据仓库(Data Warehouse)的结合,有助于实现原始数据与结构化数据的统一管理。
- 高效的数据处理与流水线:从数据采集到模型训练,需要自动化、流水线化的数据处理能力。Apache Spark、Flink等流批处理框架,以及Kubernetes支持的容器化数据流水线,能够提升数据预处理和特征工程的效率。
- 数据安全与合规性:随着数据隐私法规(如GDPR)的完善,基础设施必须集成加密、访问控制和审计功能,确保数据在存储、传输和使用过程中的安全合规。
- 实时数据接入与低延迟:对于实时AI应用(如自动驾驶、金融风控),基础设施需支持实时数据流接入(如Apache Kafka),并提供低延迟的数据查询与服务能力。
二、基础软件开发:AI的“引擎”与“工具箱”
基础软件是AI技术栈的核心,它提供了开发、训练和部署模型所需的工具与框架。其发展需聚焦以下方向:
- 通用且高效的深度学习框架:TensorFlow、PyTorch等框架已成为行业标准,但未来需进一步优化分布式训练性能、降低资源消耗,并提升对边缘计算等场景的支持。开源生态的繁荣是关键,鼓励社区贡献与模块化扩展。
- 自动机器学习(AutoML)与低代码平台:为降低AI开发门槛,基础软件应集成AutoML工具,自动化模型选择、超参数调优等流程。低代码/无代码平台允许领域专家无需深入编程即可构建AI应用,加速AI民主化。
- 模型部署与运维(MLOps)工具链:模型从开发到生产环境部署常面临“最后一公里”难题。MLOps工具需涵盖模型版本管理、持续集成/持续部署(CI/CD)、监控与回滚等功能,确保模型在动态数据环境中的稳定运行。
- 跨平台与异构计算支持:AI计算日益多样化,涉及CPU、GPU、TPU乃至专用AI芯片。基础软件需提供统一的编程接口和运行时,实现跨硬件平台的高效执行,如通过ONNX(开放神经网络交换)格式促进模型互操作性。
- 可解释性与伦理AI工具:随着AI决策影响日增,基础软件应集成可解释性(XAI)工具,帮助开发者理解和调试模型行为。内置偏见检测、公平性评估等功能,助力构建负责任的AI系统。
三、协同发展:数据基础设施与基础软件的融合
数据基础设施与基础软件并非孤立存在,它们的深度集成是释放AI潜力的基石。例如:
- 数据流水线可直接与训练框架对接,实现从数据到模型的端到端自动化。
- 基础设施的元数据管理可增强模型的可追溯性,辅助MLOps实践。
- 存储系统的性能优化(如高速缓存、数据局部性)能大幅提升训练效率。
随着边缘AI、联邦学习等新范式的兴起,基础设施与基础软件需共同演进,支持去中心化数据协作与隐私保护计算。
人工智能的最佳利用,本质上是数据、算法与计算的交响曲。构建弹性和智能的数据基础设施,搭配灵活且强大的基础软件开发环境,才能为AI创新提供坚实支撑。企业与开发者应摒弃“重模型、轻数据”的旧思维,从系统层面规划AI技术栈,方能在智能化浪潮中抢占先机。只有夯实数据根基,精进软件工具,我们才能真正驾驭人工智能,赋能千行百业的数字化转型。
如若转载,请注明出处:http://www.ywtdzjx.com/product/37.html
更新时间:2026-04-16 19:15:28